
Introduction
Planning is essential before starting any project. A well-designed plan saves time later when unexpected issues arise or when the project grows more complex. Good planning also adds clarity: it helps determine the methods to use, where to store data and models, and whether there is sufficient computational power for efficient experimentation. A structured plan minimizes delays and unnecessary stress.
A structured plan also supports reproducibility—either for yourself when revisiting the project or for others who may need to replicate or extend your work.
The Data Science Project Lifecycle typically includes the following stages: Problem Definition, Data Collection, Data Preparation, Exploratory Data Analysis (EDA), Model Building and Evaluation, Deployment, and Monitoring and Maintenance. Documentation is a critical element that spans the entire lifecycle.
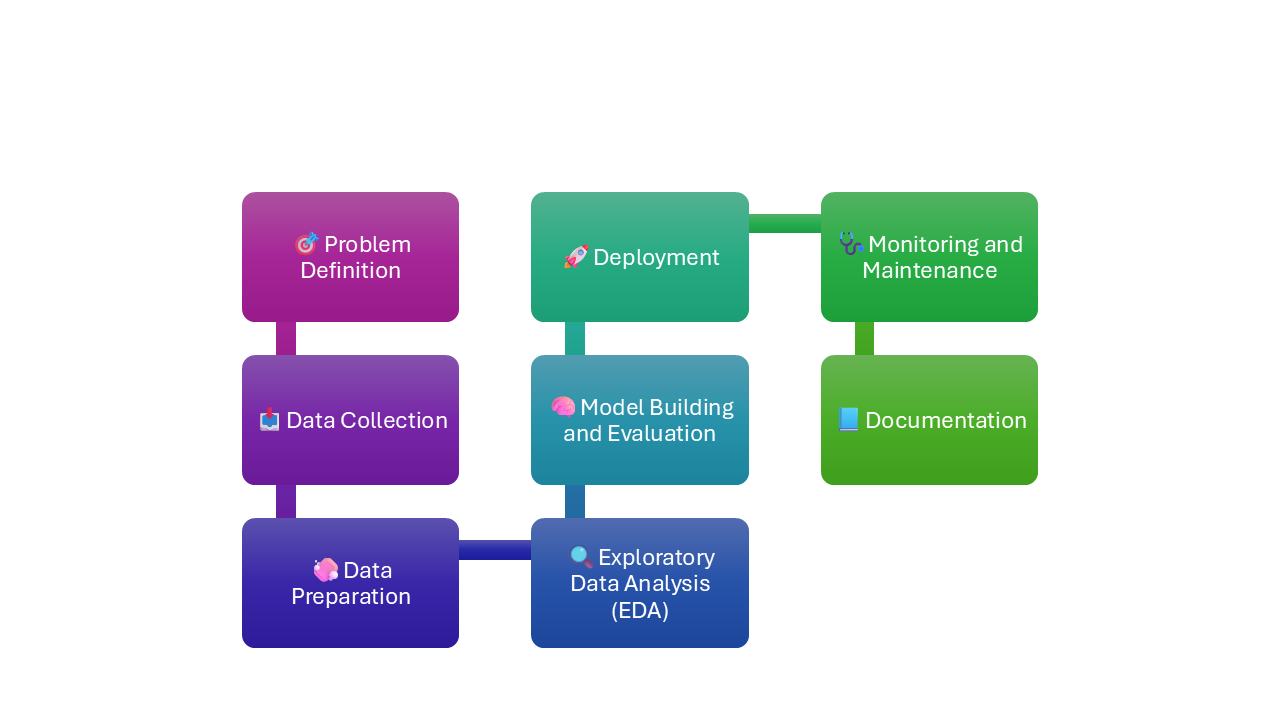 Figure 1. Data science lifecycle.
Figure 1. Data science lifecycle.
Lifecycle Stages
1. 🎯 Problem Definition
Define Objectives, Success Criteria, and Stakeholders
The first step is clearly identifying the problem. Why does it matter? Is it worth solving? Has anything similar been attempted before?
It’s important to ensure the problem is both necessary and feasible. People sometimes take on tasks outside their expertise or beyond available resources (e.g., limited domain knowledge, insufficient computational power, or lack of tools).
Using the SMART framework helps in defining objectives:
- Specific – What exactly do you want to solve?
- Measurable – Can you assess the outcome using metrics?
- Achievable – Do you have the capacity and resources to solve it?
- Relevant – Does the problem matter within its domain or to the business?
- Time-bound – Can it be completed within a reasonable timeframe?
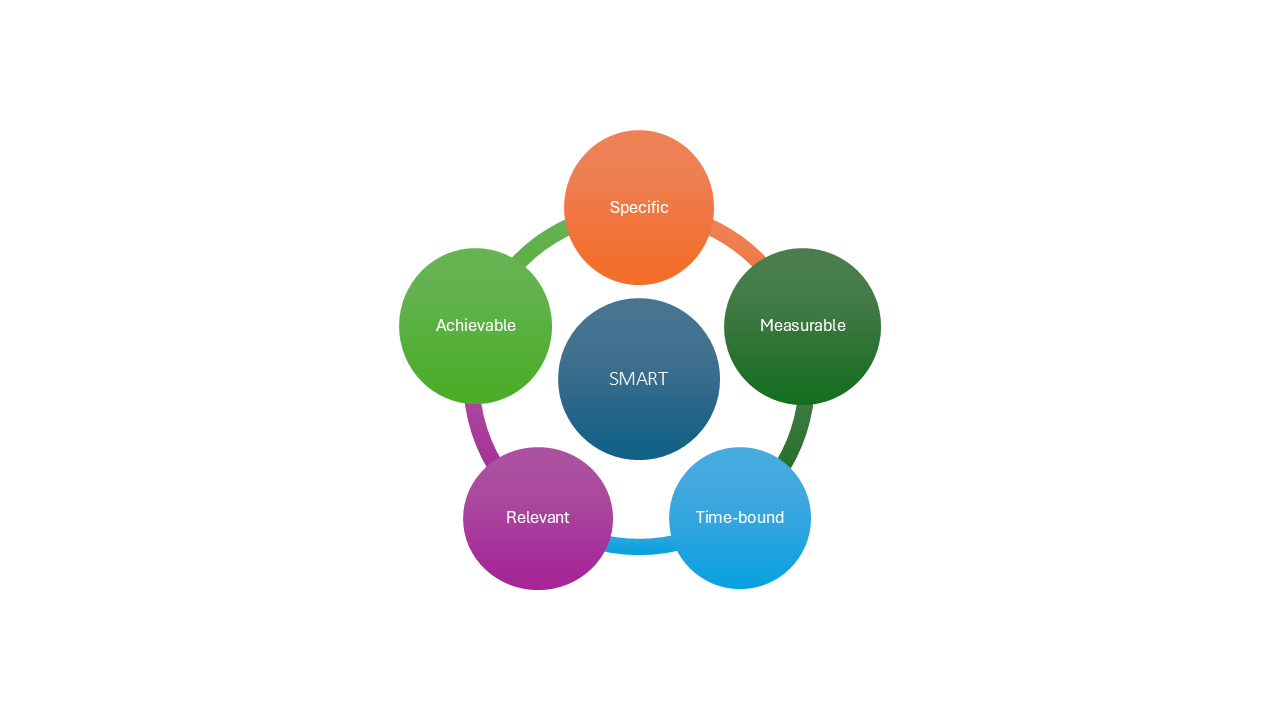 Figure 2. SMART Framework Diagram.
Figure 2. SMART Framework Diagram.
A solid understanding of the topic and thorough background research are crucial at this stage.
2. 📥 Data Collection
Gather Raw Data from Internal or External Sources
Key questions include: What data do we need? Where will it come from? How will we store and back it up?
Public datasets are convenient because they are often pre-processed, but real-world problems typically require collecting proprietary data. This may take significant time and requires planning for tools, protocols, storage, and any ethical considerations.
Data quality has a direct impact on model performance: “Garbage in, garbage out.” Simple models can work well with high-quality data, while sophisticated models can fail with poor data.
Good data quality usually implies:
- Having enough data (the definition of “enough” depends on the problem).
- Proper representation of categories or classes.
- Avoiding unnecessary or redundant features.
- Considering real-world class imbalance when appropriate.
Always back up your data to prevent loss of weeks of work.
3. 🧼 Data Cleaning and Preparation
This stage involves preprocessing, cleaning, handling missing values, fixing inconsistent formats, addressing outliers, and applying necessary transformations (e.g., normalization, feature scaling). Good planning ensures these steps are systematic and reproducible.
4. 🔍 Exploratory Data Analysis (EDA)
Understand Patterns, Distributions, and Correlations
EDA often overlaps with preprocessing. You need to understand what the data looks like before deciding how to clean it: determining the number of outliers, the extent of missing values, identifying patterns, assessing distributions, and measuring correlations between variables or between features and the target. This step provides a complete picture of the dataset’s structure.
5. 🧠 Model Building and Evaluation
Model Building
Select and Train Algorithms, Tune Hyperparameters
After understanding the data, the project moves to model development. Typically, you test several models, compare them, and select the best one based on performance metrics and available computational resources. If multiple models perform similarly, the simpler one is often preferable for interpretability and speed.
Hyperparameter tuning can be done via techniques such as grid search, random search, Bayesian optimization, or manual tuning. A common strategy is to start simple and increase complexity only when necessary.
Evaluation
Models must be compared using appropriate metrics. Different problems require different evaluation metrics. For example:
- F1 Score for imbalanced classification problems.
- Accuracy for balanced classification problems.
- Precision when False Positives are costly (e.g., identifying potential fraud).
- Recall when False Negatives are costly (e.g., medical diagnosis).
- AUC-ROC (Area Under the Receiver Operating Characteristic Curve) for ranking and threshold-independent comparison.
Choosing the right metric is essential for meaningful evaluation and to confirm the model meets the success criteria defined in Stage 1.
6. 🚀 Deployment
Package Model, Create APIs, Automate Pipelines
Once the model meets the criteria, it needs to be made accessible to users or integrated into a system. This may involve:
- Publishing the project code in a repository (e.g., GitHub).
- Packaging the model and its dependencies.
- Exposing the model’s prediction functionality as an API (Application Programming Interface).
- Building a simple web application or integrating it into an existing platform.
The method of deployment depends on the project’s context, intended users, and the technical environment.
7. 🩺 Monitoring and Maintenance
Track Model Drift, Retrain as Needed
Real-world data, user behavior, and underlying trends change over time. Monitoring helps detect a drop in performance (known as model drift), after which retraining or updating the model and pipeline may be necessary. Maintenance also includes adapting the system to new user needs or changing requirements.
8. 📘 Documentation
Documentation supports both deployment and reproducibility. It should explain:
- How the project works (design and architecture).
- How to use the deployed system.
- How others can replicate or validate your results (including data sources, preprocessing steps, and model details).
Conclusion
Iteration is central to the entire lifecycle. Feedback, improvements, and repeated cycles through the stages help ensure the final product is reliable, robust, and reproducible. The process is rarely linear and often requires revisiting earlier stages based on new findings or requirements.